Data Sources & Methodology
Data Sources
VSET draws on the latest available year from three major Eurostat surveys. The codebook links provide researchers with full documentation of the original datasets, including variable definitions and coding schemas.
Methodology
This section describes how VSET transforms three official Eurostat sources—AES 2022, LFS 2023 (yearly), and SES 2018—into VSET. The goal is to ensure that variables, categories, and keys are consistent across surveys, enabling reliable cross-country and cross-sector analysis of the data.
The methodology has two stages:
- Preprocessing: Cleaning, harmonizing, and enriching each source dataset individually.
- Merging: Joining the harmonized outputs into the VSECAT database.
In the next figure, a high-level view of the whole methodology used to create VSET is depicted. In the following sections, all the process will be detailed.
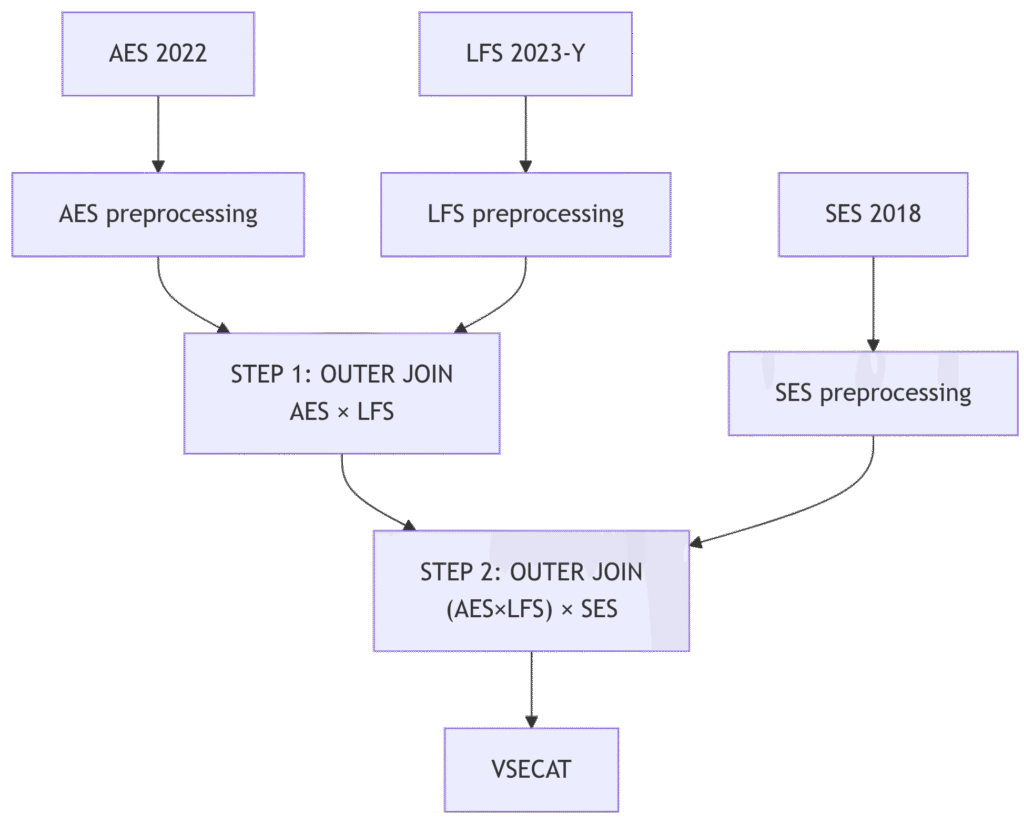
Preprocessing
Objectives and Common Principles
The preprocessing stage ensures that AES, LFS, and SES share:
- Common variable names and definitions (e.g., COUNTRY, SEX, AGE_GROUPS, ISCO-08, FTPT, LOCSIZEFIRM).
- Consistent category labels (e.g., Male/Female, Full-time/Part-time, firm size bands).
- Standardized classifications:
- Occupations: ISCO-08 codes normalized to the same digit level and linked to official titles. The maximum size of digit level is 2-digit.
- Education: ISCED-11 aligned levels and harmonized fields of study.
- Derived indicators for comparability:
- AGE_GROUPS: 14–19, 20–29, 30–39, 40–49, 50–59, 60+.
- ORIGIN: National / Foreigner (where parental country data exists).
- Special code handling: “Not applicable” and “Not available” standardized to readable labels.
- SES-specific adjustments: Currency normalization and aggregation to a merge-ready grain.
These steps create a harmonized structure that allows the next stage, merging, to combine the datasets without ad-hoc fixes.
AES 2022
Variables retained and standardized. Some variables have been renamed as a form of standardizing them across databases. Original names are in parentheses: COUNTRY, SEX, AGE, CITIZENSHIP (CITIZEN), COUNTRY_FATHER (BIRTHFATHER), COUNTRY_MOTHER (BIRTHMOTHER), HATLEVEL, HATFIELD, MAINSTAT, JOBSTAT, FTPT, LOCSIZEFIRM, ISCO-08 (JOBISCO).
Variables which have had their categories mapped are shown next. Mappings are done to harmonize categories across databases. The others have been left unchanged.
- SEX:
- 1 → Male
- 2 → Female.
- CITIZENSHIP, COUNTRY_FATHER and COUNTRY_MOTHER:
- 1 → CountryOfSurvey (placeholder replaced by actual COUNTRY at later stages)
- 2 → Another EU Country
- 3 → A non EU Country
- 4 → Another Country
- MAINSTAT:
- 10 → Employed
- 20 → Unemployed
- 31 → Student, pupil
- 32 → Retired
- 33 → Unable to work due to long-standing health problems
- 34 → Compulsory military or civilian service
- 35 → Fulfilling domestic tasks
- 36 → Other
- JOBSTAT:
- -2 → Not applicable
- 11 → Self-employed person with employees
- 12 → Self-employed person without employees
- 20 → Employee
- 30 → Family worker (unpaid)
- FTPT:
- -2 → Not applicable
- 1 → Full-time job
- 2 → Part-time job
- LOCSIZEFIRM: they have been consolidated to common groups with the maximum precision shared across the three datasets.
- -2 → Not applicable
- 10 → 1_49
- 11 → 1_49
- 12 → 50_249
- 13 → GE_250
- 14 → 1_49
- 15 → 1_49
- HATFIELD:
- -2 → Not applicable
- 0 → Generic programmes and qualifications
- 1 → Education
- 2 → Arts and humanities
- 3 → Social sciences, journalism and information
- 4 → Business, administration and law
- 5 → Natural sciences, mathematics and statistics
- 6 → Information and Communication technologies (ICTs)
- 7 → Engineering, manufacturing and construction
- 8 → Agriculture, forestry, fisheries and veterinary
- 9 → Health and welfare
- 10 → Services
ISCO-08 codes: Prefix “OC” removed from the 2-digit ISCO code; ISCO-08 corresponding title attached. ISCO-08 codes are available in Annex — ISCO-08 Sub-Major Groups
Education: HATLEVEL aligned to ISCED-11. The ISCED codes are available in Annex — ISCED Coding for HATLEVEL
- AGE_GROUPS: Created from AGE numeric variable by binning the numerical age to the following bins: 14-19, 20-29, 30-39, 40-49, 50-59, 60+. This binning is done to match the AGE variable in SES, which is provided already binned for anonymization reasons.
- ORIGIN: Foreigner if either parent (COUNTRY_FATHER or COUNTRY_MOTHER) coded as 2/3/4 (Different from CountryOfSurvey); else National.
LFS 2023
Variables retained and standardized. Some variables have been renamed as a form of standardizing them across databases. Original names are in the parentheses: COUNTRY, SEX, AGE, CITIZENSHIP, COUNTRY_BIRTH (COUNTRYB), COUNTRY_FATHER (COBFATH), COUNTRY_MOTHER (COBMOTH), HATLEVEL, HATFIELD, EMPSTAT, MAINSTAT, ILOSTAT, JOBSTAT (STAPRO), FTPT, TEMP, TEMPDUR, NUMJOB, LOCSIZEFIRM (SIZEFIRM), HOMEWORK, ISCO-08 (ISCO08_3D).
Variables which have had their categories mapped are shown next. Mappings are done to harmonize categories across databases. The others have been left unchanged.
- SEX:
- 1 → Male
- 2 → Female.
- EMPSTAT:
- 1 → Employed
- 2 → Not employed
- 9 → Not applicable
- MAINSTAT:
- 1 → Employed
- 2 → Unemployed
- 3 → Retired
- 4 → Unable to work due to long-standing health problems
- 5 → Student, pupil
- 6 → Fulfilling domestic tasks
- 7 → Compulsory military or civilian service
- 8 → Other
- 9 → Not applicable
- ILOSTAT:
- 1 → Employed
- 2 → Unemployed
- 3 → Outside the labour force
- JOBSTAT:
- 0 → Self-employed person
- 3 → Employee
- 4 → Family worker (unpaid)
- 9 → Not applicable
- FTPT:
- 1 → Full-time job
- 2 → Part-time job
- 9 → Not applicable
- TEMP:
- 1 → Permanent job
- 2 → Fixed-term job
- 9 → Not applicable
- TEMPDUR:
- 1 → < 1 month
- 2 → 1 – 3 month
- 3 → 3 – 6 month
- 4 → 6 – 12 month
- 5 → 12 – 18 month
- 6 → 18 – 24 month
- 7 → 24 – 36 month
- 8 → > 36 month
- 9 → Not applicable
- NUMJOB:
- 1 → Only one job
- 2 → Two jobs
- 3 → Three jobs or more
- 9 → Not applicable
- LOCSIZEFIRM: they have been consolidated to common groups with the maximum precision shared across the three datasets.
- 10 → 1_49
- 11 → 1_49
- 12 → 50_249
- 13 → GE_250
- 14 → 1_49
- 15 → 1_49
- 99 → Not applicable
- HOMEWORK:
- 1 → Mainly works at home
- 2 → Sometimes works at home
- 3 → Never works at home
- 9 → Not applicable
- HATFIELD:
- -2 → Not applicable
- 0 → Generic programmes and qualifications
- 1 → Education
- 2 → Arts and humanities
- 3 → Social sciences, journalism and information
- 4 → Business, administration and law
- 5 → Natural sciences, mathematics and statistics
- 6 → Information and Communication technologies (ICTs)
- 7 → Engineering, manufacturing and construction
- 8 → Agriculture, forestry, fisheries and veterinary
- 9 → Health and welfare
- 10 → Services
ISCO-08 codes: Normalized from 3-digit to 2-digits; ISCO-08 corresponding title attached. ISCO-08 codes are available in Annex — ISCO-08 Sub-Major Groups
Education: HATLEVEL aligned to ISCED-11 at the same level as found in AES. The ISCED codes are available in Annex — ISCED Coding for HATLEVEL
- AGE_GROUPS: Created from AGE numeric variable by binning to the bins 14-19, 20-29, 30-39, 40-49, 50-59, 60+. This binning is done to match the AES variable in SES, which is provided already binned for anonymization reasons.
- ORIGIN: National if either parent marked NAT (LFS code for National); else Foreigner.
- AGE_GROUPS: Created from AGE numeric variable by binning the numerical age to the following bins: 14-19, 20-29, 30-39, 40-49, 50-59, 60+. This binning is done to match the AGE variable in SES, which is provided already binned for anonymization reasons.
- ORIGIN: National if either parent marked NAT (LFS code for National); else Foreigner.
SES 2018
Variables retained and standardized. Some variables have been renamed as a form of standardizing them across databases. Original names are in the parentheses: COUNTRY, SEX (B21), AGE (B22_CLASS), HATLEVEL (B25), FTPT (B27), LOCSIZEFIRM (A12_CLASS), ISCO-08 (B23), ANNUAL_EARNINGS (B41), MONTHLY_EARNINGS (B42), HOURLY_EARNINGS (B43).
Variables which have had their categories mapped are shown next. Mappings are done to harmonize categories across databases. The others have been left unchanged.
- SEX:
- M → Male
- F → Female.
- FTPT:
- FT→ Full-time job
- PT → Part-time job
- LOCSIZEFIRM:
- 1_49 → 1_49
- 50_249 → 50_249
- GT_250 → GE_250
- ALL → 1_49
- HATLEVEL:
- G1 → Group 1
- G2 → Group 2
- G3 → Group 3
- G4 → Group 4
ISCO-08 codes: Normalized from 3-digit to 2-digits; ISCO-08 corresponding title attached. ISCO-08 codes are available in Annex — ISCO-08 Sub-Major Groups
Education: HATLEVEL is already aggregated to ISCED-11 groupings as shown in Annex — ISCED Coding for HATLEVEL
- AGE_GROUPS: directly obtained from AGE, as AGE is already binned in SES.
- The SES earnings have been aggregated by obtaining some statistical values for each earning variable. This is done so that SES can be combined with the other datasets.
- SES is grouped by: COUNTRY, SEX, ISCO-08, ISCO-08_Title, AGE_GROUPS, FTPT, LOCSIZEFIRM.
- Statistics computed for each earnings variable for each of the previous groups: ANNUAL_EARNINGS, MONTHLY_EARNINGS and HOURLY_EARNINGS – mean, median, std, min, max.
All earnings of countries not using EUR are converted to EUR using the official SES exchange rates for 2018. The exchange rate table can be found in Annex — SES Exchange Rates 2018.
- AGE_GROUPS: Created from AGE numeric variable by binning the numerical age to the following bins: 14-19, 20-29, 30-39, 40-49, 50-59, 60+. This binning is done to match the AGE variable in SES, which is provided already binned for anonymization reasons.
- ORIGIN: National if either parent marked NAT (LFS code for National); else Foreigner.
Harmonization Outcome
After preprocessing:
- Shared keys across all datasets: COUNTRY, SEX, AGE_GROUPS, HATLEVEL, ISCO-08, ISCO-08_Title, FTPT
- Shared keys across AES-LFS: CITIZENSHIP, HATFIELD, MAINSTAT, JOBSTAT, LOCSIZEFIRM, ORIGIN.
- Consistent category labels: Same wording for categorical variables such as sex, working time, firm size, education domains, etc.
- SES earnings normalized and aggregated: Ready to match AES/LFS slices.
- Special codes harmonized: “Not applicable” and “Not available” standardized; placeholders replaced by actual country names.
This alignment is the foundation for the next step, Merging, where we combine the three harmonized datasets into VSECAT.
Merging
Objectives and inputs
After preprocessing, the three sources (AES 2022, LFS 2023‑Y, SES 2018) share a common set of variables, labels, and classifications. The merging stage:
- Preserves maximum coverage across countries and breakdowns by using outer joins.
- Aligns at two grains:
- A rich population grain for AES×LFS (demographics, labour status, education, firm size, etc.).
- A reduced analytical grain for linking SES earnings (country, sex, occupation, age group, working time, plus occupation title).
- Resolves duplicate groups across sources with a clear priority order, producing a single entry per group.
Pre-join quality filters
Before any join, each input table is filtered to remove rows that would undermine comparability:
- Occupation title must be informative: rows whose ISCO‑08_Title equals “Not available” or “Not applicable” (case‑insensitive) are discarded in all three inputs. This ensures that every record entering the merge has a valid occupational attribution.
- Free‑text “No answer”: any row that contains the literal string “No answer” in any variable is removed (the check is done row‑wise and case‑insensitive). This avoids mixing explicit item non‑response with valid categories.
Join keys and sequence
- Merge AES and LFS (rich population grain). AES and LFS are merged with an outer join on the following key set: COUNTRY, SEX, ISCO‑08, AGE_GROUPS, ISCO‑08_Title, HATLEVEL, FTPT, CITIZENSHIP, HATFIELD, MAINSTAT, JOBSTAT, LOCSIZEFIRM, COUNTRY_MOTHER, COUNTRY_FATHER, ORIGIN. This retains the demographic, education, labour‑status and firm‑size detail that characterize the population tables.
- Merge the AES×LFS result with SES (earnings grain). The intermediate table is then outer‑joined with SES on a reduced key set tailored to SES earnings coverage:
COUNTRY, SEX, ISCO‑08, AGE_GROUPS, ISCO‑08_Title, FTPT.
Because SES is linked on fewer keys than AES×LFS, earnings indicators are conditioned only by: country, sex, occupation (2‑digit ISCO‑08), age group, and full/part‑time. They are not conditioned by other AES/LFS dimensions such as HATLEVEL, HATFIELD, MAINSTAT, JOBSTAT, CITIZENSHIP, ORIGIN, or LOCSIZEFIRM. In practice, this means the same SES earnings for a given (COUNTRY, SEX, ISCO‑08, AGE_GROUPS, FTPT) combination will align with all corresponding AES/LFS segments that differ only along those additional dimensions. This reflects the lower number of shared variables of the merge keys in SES.
Both joins are outer, so combinations present in any source are retained for downstream analysis; missing elements from other sources remain empty instead of removed.
Coalescing rule
After joining, some variables may be present in multiple source‑suffixed versions (e.g., VARIABLE_aes, VARIABLE_lfs, VARIABLE_ses) or also as an unsuffixed column carried by the merge. The pipeline coalesces these into one column per variable, following a strict priority order:
- AES value if available (_aes)
- otherwise LFS value (_lfs)
- otherwise the unsuffixed value (if created by the merge)
- otherwise SES value (_ses)
Empty strings are treated as missing before applying this precedence. After coalescing, the redundant suffixed columns are dropped. Join keys are excluded from coalescing (they are already harmonized).
This rule ensures a deterministic resolution of overlaps while reflecting a design choice to prioritize AES, then LFS, and only then SES for any non‑key variable that appears in more than one source.
Exact de-duplication with counts
The merged table is scanned for fully identical rows (same values in all columns). Identical rows are collapsed into a single record and an auxiliary counter (N_instances) is added to indicate how many duplicates existed. This provides a traceable audit of record multiplicity without inflating statistics.
Final categorical alignment
To keep categories stable and efficient for analysis:
- Low‑cardinality columns are converted to categorical data type (only when it’s safe to do so)
- Category sets are unified and ordered consistently across the table.
This step avoids subtle inconsistencies when grouping or pivoting later.
What VSET represents
- The final table is a wide analytical base where population descriptors (from AES/LFS) and earnings indicators (from SES) are aligned at the (COUNTRY, SEX, ISCO‑08, AGE_GROUPS, FTPT) grain. Additional AES/LFS dimensions (education level/field, labour status, citizenship/origin, firm size) remain available to segment populations, but earnings are not further broken down by those dimensions at merge time.
- Because both joins are outer, the merged dataset may contain cells without earnings (where SES has no observation for a given key) or population cells without complements in the other surveys. These are expected and signal true coverage differences across sources.
Practical notes for users of VSET
- Occupation filtering: records without a usable occupation code are dropped before the merge—analyses should assume valid ISCO‑08 code and title in every final row.
- “No answer”: any row containing this literal answer anywhere is removed; users will not encounter this residual category.
- Coalesced variables: where the same concept appears from multiple surveys, VSET provides one unified column following the precedence described above. Users do not need to manage suffixed variants.